
Fig. 1 Perceptró: model duna neurona
|
"XARXES NEURONALS: APLICACIÓ AL RECONEIXEMENT DE PATRONS" |
Objectius de la pràctica:
1. El Perceptró: una xarxa neuronal simpleLa neurona dun perceptró, que té com a funció de transferència (FT) un limitador, es mostra en la Fig. 1. El codi MATLAB que permet calcular la sortida daquesta neurona es presenta també en la mateixa figura.
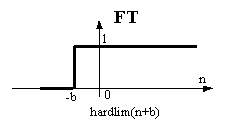
Cada entrada es ponderada amb el correspoent pes W, i la suma de les entrades ponderades és enviada a la funció de transferència de tipus limitador. Aquesta funció de transferència, que MATLAB lanomena hardlim, retorna un "0", o bé, un "1" depenent de quin és el rang de lentrada. La representació gràfica daquest comportament es pot veure en la Fig. 2. Es pot veure com el llindar dactivació es pot variar afegint una constant, b. Aquest paràmetre sanomena offset o bias (b).
Una xarxa neuronal formada per neurones de tipus perceptró està formada per una sola capa amb S neurones tipus perceptró connectades a R entrades a través dun conjunt de pesos W(i,j) tal com es mostra en la Fig. 3. Els indexos "i" i "j" indiquen que el pes W(i,j) es el pes de la connexió de la j-èsima entrada de la i-èsima neurona (per tant de la i-èsima component de la sortida de la xarxa).
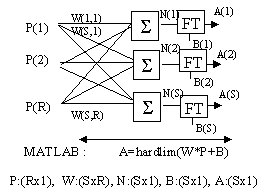
Fig. 3 Xarxa neuronal formada per perceptrons (FT es hardlim, Fig.2)
1.1 InicialitzacióLa funció rands sutilitza per inicialitzar els pesos a valors aleatoris. Així per exemple, una xarxa neuronal formada per 8 neurones i 4 entrades sinicialitzaria mitjançant
R=4; S=8; [W,B]=rands(S,R); % R i S son les dimensions del vector dentrada i sortida resp.
Una xarxa neuronal formada per perceptrons és entrenada perquè respongui davant dun vector dentrada amb el corresponent vector objectiu de sortida, els elements del qual son un "0", o bé, un "1". La regla daprenentatge és aplicada a cada neurona per tal de determinar el nou conjunt de valors dels pesos després de la darrera presentació de les entrades a la xarxa. Els canvis en els elements de la matriu de pesos es calcula mitjançant la funció de MATLAB learnp, que retorna el canvis sobre la matriu de pesos a partir del vector dentrades P, el vector de sortides A (calculat a partir del vector de pesos abans dactualitzar els pesos) i el vector de sortides objectiu T
A continuació es presenta el codi MATLAB que presenta a un perceptró un vector entrades P i actualitza els pesos mitjançant la regla daprenentatge i el vector de sortides objectiu T
[dW,dB]=learnp(P,A,T);
W=W+dW;
B=B+dB;
"per tot i, ...
Aquestes operacions es poden resumir en les següents equacions:
![]()
Els vectors patró són presentats a la xarxa neuronal un darrera de laltre. Si la sortida de la xarxa és correcta no saplica cap canvi. En cas contrari, els pesos i els offsets sactualitzen utilitzant la regla daprenentatge del perceptró. Quan sha presentat el conjunt de tots els patrons diem que sha finalitzat una època (epoch). Si després de presentar el conjunt de tots els patrons cap dells presenta error, lentrenament finalitza. En aquest moment, si es presenta qualsevol entrada patró a la xarxa aquesta respondrà amb la sortida objectiu desitjada. Si un vector Pi que no està contingut en el conjunt dentrenament es presenta a lentrada de la xarxa aquesta intentarà generalitzar responent amb una sortida similar al vectors objectiu corresponents als vectors patró dentrada que més sassemblin al vector dentrada Pi.
El codi MATLAB per entrenar un perceptró és
el següent:
MATLAB disposa duna funció que realitza tot
el procés dentrenament presentat amb el codi anterior duna sola
vegada. Aquesta funció és la funció trainp.
1.4 Exemple daplicació: implementació de la funció lògica OR
Fent ús de tota la informació presentada
fins el moment es demana entrenar una xarxa neuronal formada per una sola
neurona de tipus perceptró per tal de què aprengui el funcionament
de la funció lògica OR.
Sortides desitjades
T(1, :) : 0 1 1 1 matriu T = [0 1 1 1] ;
2. Backpropagation: un mecanisme daprenentatge eficient
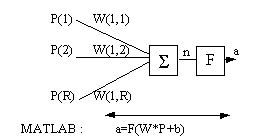
Una neurona duna xarxa de backpropagation amb R entrades es pot representar simbòlicament mitjançant la Fig. 4. Cada entrada és ponderada amb un pes W. La suma de les entrades ponderades, junt amb un offset, constitueixen lentrada de la funció de transferència F. Les neurones duna xarxa de backpropagation poden utilitzar qualsevol funció F diferenciable per a generar la sortida de la xarxa
Les xarxes de backpropagation utilitzen sovint la funció de transferència log-sigmoidal que en MATLAB simplementa mitjançant la funció logsig. La representació gràfica daquesta funció de transferència es presenta en la Fig. 5. La funció logsig genera sortides entre 0 i 1 al variar lentrada de la neurona des de valors positius a valors negatius. Aquesta funció de transferència es pot utilitzar amb offset, o bé, sense. Els offsets ofereixen a la xarxa un grau de llibertat més alhora daprendre el comportament duna determina funció. La seva utilització augmenta les possibilitats de què la xarxa trobi una solució acceptable, mentre que a la vegada redueixen el nombre dèpoques daprenentatge necessàries.
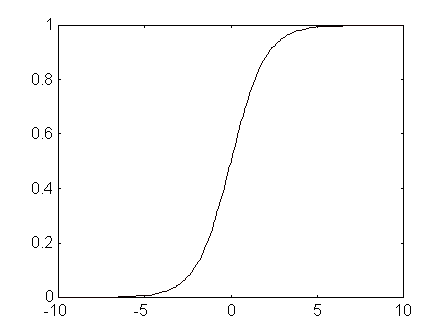
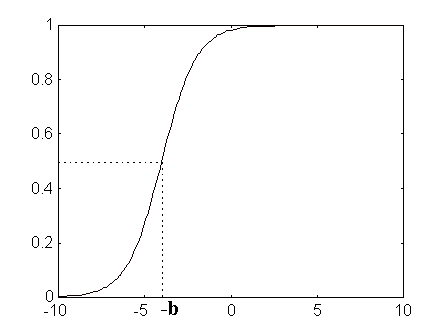
Fig. 5 Backpropagation: funció de transferència logsig (n) i logsig(n+b) .
De forma alternativa, les xarxes de backpropagation poden utilitzar la funció de transferència (F) tan-sigmoidal implemanta en MATLAB amb la funció tansig. Aquesta funció es presenta en la Fig. 6.
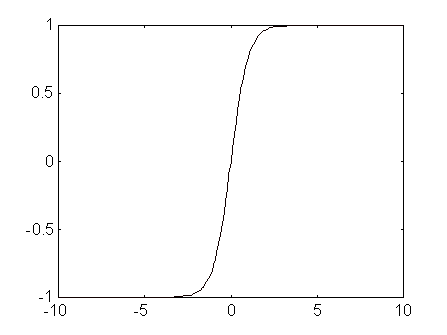
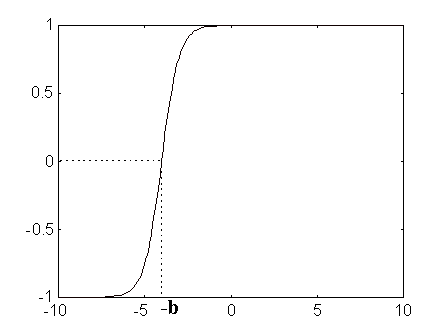
Fig. 6 Backpropagation: funció de transferència tansig(n)i tansig(n+b).
De vegades, també es pot utilitzar la funció de transferència lineal que el MATLAB implementa amb la funció purelin. Aquesta funció es presenta en la Fig. 7.
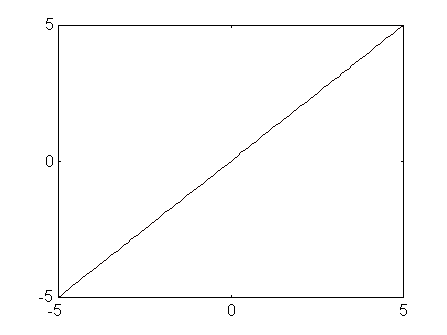
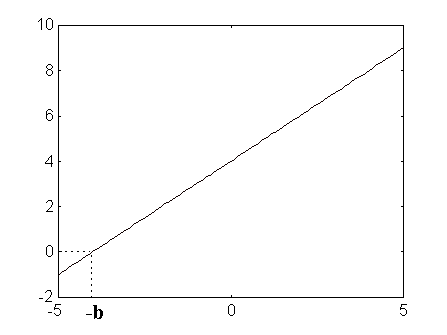
Fig. 7 Backpropagation: funció de transferència purelin(n) i purelin(n+b)
En la Fig. 8 es presenta una xarxa neuronal amb S neurones log-sigmoidals amb R entrades. Les xarxes de backpropagation sovint tenen una o més capes ocultes de neurones sigmoidals seguides per una capa de sortida de neurones lineals. Múltiples capes de neurones amb funcions de transferència no lineals permeten a la xarxa laprenentatge de relaciones lineals i no lineals entre lentrada i la sortida.
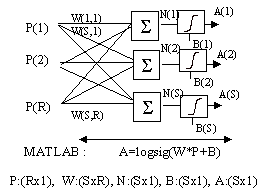
Fig. 8 Backpropagation: estructura duna xarxa neuronal duna capa
En el cas dutilitzar xarxes amb múltiples capes, afegirem el numero de la capa als noms de les matrius i vectors associats amb la capa. Així, la matriu de pesos i el vector de sortides de la capa 2 duna xarxa sanomenaran W2 i A2 respectivament. En la Fig. 9 es presenta una xarxa de backpropagation amb dues capes una tan-sigmoidal i una altra de lineal que fan servir aquesta notació.
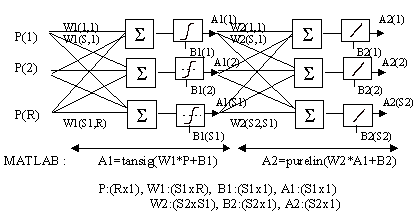
Fig. 9 Backpropagation: estructura duna xarxa neuronal de dues capes
2.1 InicialitzacióLa inicialització de la matriu de pesos duna xarxa de backpropagation es fa amb valors aleatoris entre -1 i 1. Aquesta inicialització aleatòria es pot fer mitjançant la funció de MATLAB rands. Així, per exemple, per una xarxa neuronal de backpropagation de dues capes, amb 5 entrades, 4 neurones a la capa oculta i 3 neurones a la capa de sortida, que sera entrenada amb els patrons P (entrades) per obtenir les sortides T, el codi dinicialització és el següent. Les matrius dentrada i de sortides desitjades (P i T) estan formades per:
P : Matriu amb Q vectors columna de 5 components. (R=5)T : Matriu amb Q vectors columna de 3 components (S2=3)
on Q son el número de vectors que sutilizaran en lentrenament i per tant el mateix número de vectors de sortida (objectiu) per comparar amb les sortides de la xarxa.
Així el codi Matlab serà :
Cal observar que el nombre dentrades de la xarxa i el nombre de neurones en la capa de sortida ve fixat pels vectors entrada/objectiu que la xarxa ha daprendre. El número de neurones en les capes ocultes es decisió del dissenyador de la xarxa. Quantes més neurones, més possibilitat de què la xarxa assoleixi una solució. En canvi, quantes més neurones més temps daprenentatge serà necessari i més grans seran les matrius de pesos. [R,Q]=size(P);
S1=4; % 4 neurones capa oculta
[S2,Q]=size(T); %
[W1,B1]=rands(S1,R); % Pesos i bias capa oculta
[W2,B2]=rands(S2,S1); % pesos i bias capa de sortida2.2 Regla daprenentatge
La regla daprenentatge donada per lalgorisme backpropagation permet lentrenament de xarxes no lineals multicapa per a aplicacions de classificació i associació de patrons. La restricció daquest algorisme és que les funcions de transferència (o activació) han de ser funcions derivables, ja que lajust dels pesos es fa seguint una algorisme de minimització de lerror quadràtic mig (LMS, Least mean squared) mitjançant la disminució del gradient (gradient descent) a cada iteració efectuada per lajust dels pesos. Per això és necessari calcular les derivades de lerror (vector delta). I lerror es defineix com la diferència entre les sortides teòriques i les reals).
Les derivades de lerror calculades a la sortida de la última capa (ja que és la única que podem comparar amb els patrons desitjats), es propaguen cap a les capes internes (ocultes). A Matlab el càlcul dels delta vectors (D) es fa amb les funcions deltalin(A,E), deltalog(A,E) i deltatan(A,E) en el cas de la capa oculta i deltalin(A,D,W), deltalog(A,D,W), deltatan(A,D,W) pel cas de capes ocultes. Els paràmetres corresponen a : A : vector de sortides, E : vector error, D i W : són els delta vectors i els pesos de la capa anterior. Sutilitza una funció o altra dacord amb la funció de transferència desitjada en cada capa.A mesura que es va propagant lerror cap a les capes ocultes, lactualització dels pesos (i bias) es fa segons aquests valors seguint amb els increments calculats daquesta forma:
DW(i,j)= lr D(i)P(i) lr : velocitat daprenentatge.
DB(i)= lr D(i) D(i) : vector delta propagat.
P(i) : Entrades de la cpa en qüestió.
La funció de Matlab [dW,dB]=learnbp(P,D,lr) es pot utilitzar amb aquest propòsit. Només cal tenir en compta que P i D shan de presentar com matrius, amb els vectors columnes corresponent a tots els patrons que es volen entrenar.
E1cas contrari es calcula el vector delta a la sortida de la xarxa i es propaga enrera (backpropagation) cap ales capes ocultes. A partir dels vecors delta de cada capa sactualitzen els pesos dacord amb la regla daprenentatge anterior. I es repeteix el procés fins que lerror sigui inferir a un llindar predeterminat.
Aquest procediment es pot fer de froma c`moda a Matlab utilitzant la funció trainbp que permet lentrenament de xarxes de varies capes. En aquest cas cal els passos a seguir son :
Per cada capa caldrà a més a més
:
- Inicialitzar (aleatoriament) les matrius W i B de pesos
i bias.
- Especificar el tipus de xarxa (funció de transferència)
en un string. Fx per exemple.
Amb tot això podem fer crides ala funció anterior com la següent, pel cas duna xarxa de dues capes :
[W1,B1,W2,B2,epochs, TR]=trainbp(W1,B1,F1,W2,B2,F2,P,T,TP)
;
2.4 Exemple daplicació: aproximació duna funció matemàtica qualsevol
Finalment, una vegada presentat com el MATLAB tracta les xarxes neuronals de backpropagation es proposa dutilitzar una daquestes xarxes per aproximar el comportament duna funció no lineal donada per lexpressió en el marge -1<t<1:
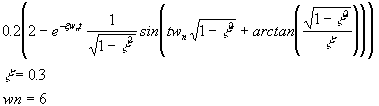
Per aixo es prendran 21 mostres de la variable t, distribuïdes entre -1 i 1 equiespaiades 01 unitats entre elles. Aquests 21 mostres sutilitzaran com senyals dentrada de la xarxa. Es pretén per tant que la xarxa sigui capaç d aproximar aquesta funció. Per tant sentrenarà la xarxa de forma que per les entrades proposades donin les sortides corresponents a la funció anterior.
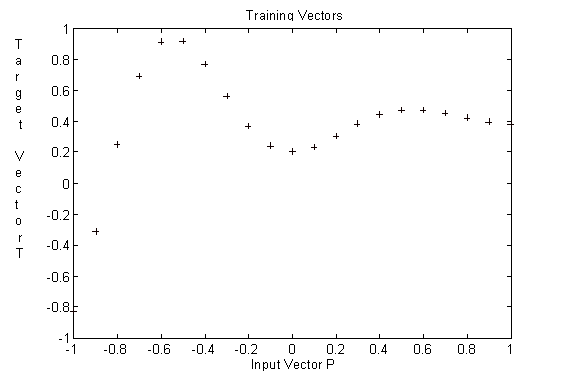
Fig. 10 Relacio entre patrons de lentrada i sortides desitjades.
Codi Matlab per representar la funció :t= -1:.1:1;
psi=0.3;
wn=6;
wd=wn*sqrt(1-psi^2);
P = t ; % Patrons de lentrada
T=0.2*(2-exp(-psi*wn*P)/sqrt(1-psi^2).*sin(wd*P+atan(sqrt(1-psi^2)/psi)));% sortides desitjades% corresponents a les 21
% entrades anteriors.
Estructura de la xarxa :
La xarxa neuronal proposada es dissenyarà amb una entrada, una sortida i dues capes. La primera capa (capa oculta) tindrà 5 neurones duna sola entrada amb funció de transferència tansigmoidal i la segona capa una única neurona de 5 entrades i funció de transferència lineal (veure figura).
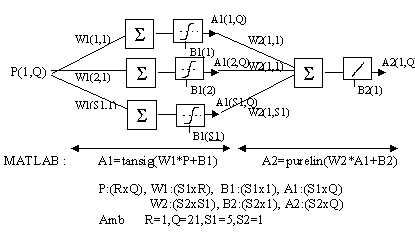
Fig. 11 Xarxa neuronal per aproximar la funció anterior
Per la implementació pots utilitzar les funcions següents de la ToolBox de Xarxes neuronals de Matlab :initff - Per la inicialització de la xarxa
trainbp - Per lentrenament de la xarxa dacord amb lalgorisme Backpropagation.
simuff - Per simular el comportament de la xarxaPer exemple, per la xarxa dela figura anterior, podem inicialitzar els pesos i bias fent :
S1 = 5;
[w1,b1,w2,b2] = initff(P,S1,'tansig',T,'purelin');Per lentrenament cal definir una sèrie de paràmetres :
df = 10; % Frequency of progress displays (in epochs).
me = 8000; % Maximum number of epochs to train.
eg = 0.02; % Sum-squared error goal.
lr = 0.01; % Learning rate.Per lentrenament de la xarxa amb els paràmetres anteriors executaríem la comanda següent :
tp = [df me eg lr];
[w1,b1,w2,b2,ep,tr] = trainbp(w1,b1,'tansig',w2,b2,'purelin',P,T,tp);i el resultat retornat son els pesos finals de cada capa i levolució de lerror a cada època. Finalment lerror es pot visualitzar fent :
ploterr(tr,eg);
Un cop entrenada la xarxa, prova el seu funcionament observant la sortida per un valor pel que no ha estat entrenada (dintre el marge compres entre -1 i 1) i compara la sortida amb la que dóna la funció original.
Nota : La matriu P, ha de contenir els 21 patrons (entrades) . Cada columna correspon a un patró (en aquest cas una columna només te un element) diferent. Per tant en aquest cas ha P sera un vector fila de 21x1.
3. Aplicació de les Xarxes Neuronals al reconeixement de patrons
Es desitja dissenyar i entrenar una xarxa neuronal que sigui capaç de reconèixer les 26 lletres de lalfabet. Es suposa que es disposa dun sistema de visió artificial capaç de digitalitzar cada lletra centrada en el camp de visió del sistema de reconeixement. El resultat daquesta digitalització es representa mitjançant una graella de 5 x 7 pixels boleans. El problema però apareix pel fet de què el sistema de visió artificial no és perfecte i junt amb la lletra digitalitzada shi afegeix soroll. Es pretén crear un sistema capaç de classificar les 5x7 entrades de forma que doni a la sortida la lletra corresponent. Prova la solució de Matlab en la demo anomenada neural. Executa :
>> neural