| Enfoc pràctic dels sistemes experts |
Enfoc pràctic dels sistemes experts
INTRODUCCIÓ
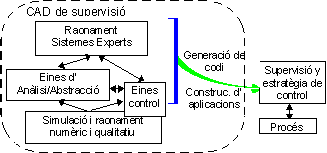
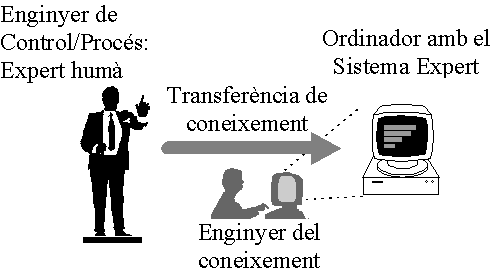
Per conseguir la transferència tecnològica de la intel·ligència artificial (IA) als sectors socioeconòmics propis de lautomatització industrial, les indústries de processos, alimentàries, i de manufactura en general, shan de concebre i construir eines que ajudin als operaris i enginyers a dissenyar i desenvolupar supervisors a semblança de les eines de disseny i desenvolupament de controladors ja existents. Proveir de "majors dosis dintel·ligència (artificial) als supervisors" és la necessitat tecnològica que promulguen les empreses que requereixen dautomatització. Aleshores, els estudis sencaminen a la màxima modularització dels supervisors a base de proporcionar-lis informació molt significativa. Aquesta informació sobtén mitjançant abstractors, generadors desdeveniments i davaluadors de prestacions de controladors industrials, i sistemes experts, recorrent-se a la concepció orientada a objecte per a la seva correcta i prolongada integració en el que anomenem Computer Aided Design (CAD) de supervisió. Aquesta nova plataforma té com a precedents els sistemes SCADA, els sistemes CACSD i els sistemes experts a temps real, com és lexemple de G2 (tema important daquesta lliçó), i serà una síntesi de la concepció dambdues plataformes. Aspectes metodològics són aleshores concebuts per emprar les esmentades eines, així com altres facilitats com la validació de petites bases de coneixement (KB) que suporten les noves eines integrades en el CAD de supervisió. Els aspectes tecnològics abarquen les tecnologies dactuadors dirigits per PC, PLC i DSP que simplantaran un futur proper en les indústries de forma generalitzada.Aleshores, aquesta lliçó intenta donar una visió general de les necessitats de supervisió mitjançant ordinadors, on shi aplica intel·ligència artificial en termes de sistemes experts dels quals G2 nés un dels exemples més representatius. A més a més, aquest sistema expert es pot connectar on-line a processos reals i té interessants capacitats de temps real que sempre vindran restringides al sistema operatiu i la plataforma (PC, SUN, etc.) que sempri.
Dins daquesta lliçó també insistirem en els aspectes de temps real que presenta el sistema expert G2. Aquesta és una visió molt il·luminadora dels aspectes de motor dinferència dun sistema expert.
La presentació daquesta lliçó tendirà en certes parts a ser molt gràfica per evitar una condensació excessiva de continguts, encara que a certes parts no sha pogut evitar. Combinarem els idiomes català i anglès doncs molta ciència es fa en anglès. Encara així i tot hem fet lesforç de presentar certs continguts fonamentals en català.
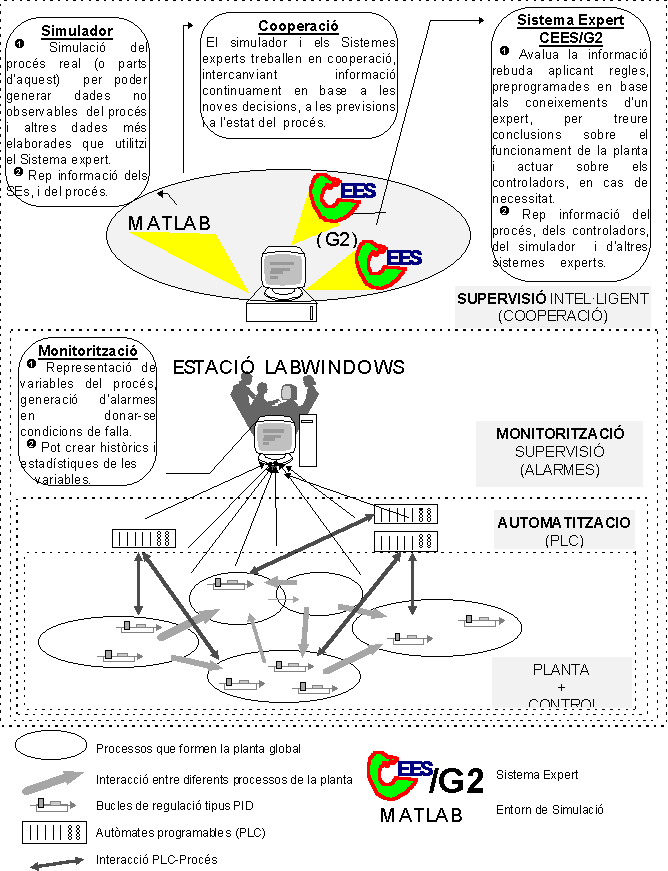
1. Què és Supervisió ?(Aplicació de Sistemes Experts en Control de Processos per Ordinador o microprocessador)
Les Necessitats dun Sistema de Supervisió poden ser
Þ Per a allò, INTEGRACIÓ deines de supervisió amb Sistemes Experts
Þ ABSTRACCIÓ DINFORMACIÓ
: Interfase entre lenginyer de procés, el de control i loperari
per desenvolupar PETITS mòduls experts de supervisió.
Þ Sistemes de Monitorització (LABWINDOWS o altres cases particulars com Siemens, FESTO, OMRON, Allen-Bradley) i entorn de disseny de controladors com pot ser MATLAB/SIMULINK.
ÞAbstractors.
ÞTecnologies de PLC principalment, i actualment sintrodueix lordinador (PC) i les arquitectures dels DSP (Digital Signal Processors).
Els Objectius Generals dIncorporar IA a la Supervisió poden ser
ÞInterfase entre lexpert de processos o enginyer de control amb les estructures de supervisió i la informació dels processos supervisats.
ÞTractament
dinformació qualitativa.
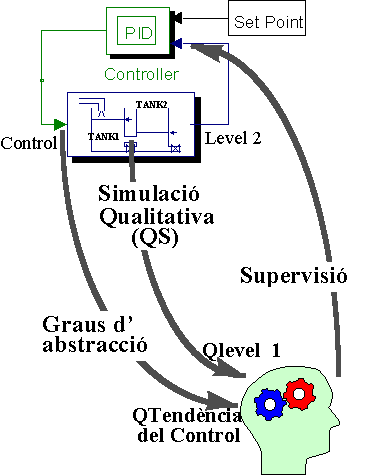
Concepció qualitativa de la supervisió
Intentem copsar el raonament expert, qualitatiu, aproximat que empren els experts quan fan de supervisors. Dels processos reals analitzem què és limportant a vista de lexpert. Els experts humans saben tractar la complexitat dels problemes mitjançant abstraccions i focalitzacions que volem automatitzar amb lordinador.
Entorn dAjut al disseny de Supervisors
La qualificació necessària es té dimplementar amb eines que permetin crear supervisors que incorporin IA. Llavors es requereix deines CAD (Computer Aided Design) que permetin crear supervisors que simplementaran en un ordinador amb qualsevol arquitectura.
2. Què és Intel·ligència Artificial ?Com ja sabeu, al llarg del curs hem anat descrivint aspectes de la IA. Això és per mor que una definició general de la IA és difícil dobtenir ¼ No hi ha cap definició tancada i definitiva que delimiti de forma precisa làrea de la IA.
Podríem demanar-nos el contrari: què és la absència dintel·ligència artificial? Aquesta IA, com la natural, podria definir-se com la tècnica de complicar-se la vida per no resoldre els problemes que es plantegen en el decurs del esdevenir de cadascun. Doncs, què seria intel·ligència? Seria una qualitat daquells sistemes, homes, animals o màquines, que serien capaços de resoldre problemes de forma òptima. Encara que aquesta aproximació és insuficient podríem emprar-la per entendre la IA: la tècnica de resoldre problemes de forma òptima, però especialment davant de problemes dèbilment estructurats. Això planteja que no es distingeixi gaire dels mètodes doptimització analítica emprats a lenginyeria, sols que lIA resol els problemes de "forma asistemàticament òptima", seguint el principi del "treballar poc maximitzant el profit" intentant devitar a caure en el "treballar molt més per treballar poc". I és que allò que pretén la IA és produir sistemes intel·ligents, perquè per produir rucs i beneits sempre hi som a temps... I estem al temps que les màquines són cada pic més "intel·ligents" i resolen molts problemes abans reservats als homes.
Seguint amb la comparació de la IA com a un procés doptimització, és fàcil dobtenir una idea a partir de lexemple de la teoria de jocs aplicada als escacs: cada jugada del contrincant genera tot un seguit de possibles contrajugades, i les contra-contra jugades i les contra-contra-contra jugades fins a varis nivells de profunditat. Després es tria la jugada que previsiblement donarà millor resultat. Quan més aprofundim larbre de cerca per trobar la millor jugada, la màquina de jugar a escacs tant molt més intel·ligent sembla. Com els ordinadors són cada pic més potents aquestes màquines de jugar a escacs cada cop juguen millor i semblen més i més intel·ligents. I lúnica cosa que fan és optimitzar el rendiment de les jugades a base de la força bruta de lavaluació de totes les possibilitats. Es això Intel·ligència? Ho és, emperò es pot millorar per ser encara més intel·ligent, doncs el jocs descacs encara és massa estructurat.
Altres aplicacions menys estructurades de la IA seria la percepció visual i no visual, la planificació de trajectòries, els sistemes tutors intel·ligents, etc., dins del món de la robòtica, i la producció industrial. Llavors, els que es cerca de la IA és que els sistemes intel·ligents sadaptin millor a noves situacions, a semblança del que farien els experts humans.
Camps importants de treball de la IA són.
- Visió per ordinador.
- Processament del llenguatge natural.
- Aprenentatge automàtic.
- Xarxes neurals.
- Sistemes experts.
- Control Automàtic i Sistemes de Producció.
- Robòtica.
- Etc.
3. Què és un Sistema Expert ?Un Sistema Expert (SE) en control de processos pot funcionar tal com segueix :
Però, insistint, què és un SE ?Un sistema expert conté un motor dinferència i una base de coneixement que es composa de una base de regles i una base de fets.
Serveix per codificar CONEIXEMENT HUMÀ en termes dexperiència, raonament aproximat, imprecisió, analogia, raonament per defecte, aprenentatge, etc. Específicament es tracta de representar el coneixement expert en un sistema basat en regles per tal de tenir un ordinador que respon com ho faria lexpert humà.
I tot això què vol dir ?
Þ Una base de regles seria un grapat de regles del tipus :
IF [succeeix_quelcom] THEN [decideix/conclou_quelcom] CERTAINTY [valoració] La part IF ... THEN de la regla, és a dir, el <succeeix quelcom>, sanomena premissa de la regla o bé precedent. La part THEN ... CERTAINTY, és a dir, el [decideix/conclou_quelcom], sanomena conclusió de la regla. La CERTAINTY [valoració] vol dir la seguretat que té lexpert de processos/control o operari en aquesta afirmació convertida en regla.
Per tant, qualsevol base de regles tindria la forma de :
Regla 1 : IF A THEN B CERTAINTY 80% Regla 2 : IF B AND C THEN D CERTAINTY 45%
.
.
.
Regla N : IF D OR E THEN F CERTAINTY 70%
ÞUna base de fets seria un grapat devidències amb certeses associades del tipus :
Una variable mesurada. Un fet com dir "Avui Plou", o dir "Possible ALARMA708, amb certesa 30%" etc. Una conclusió duna o vàries regles, com per exemple "Diagnòstic PROBLEMES AMB LA VÀLVULA 12, amb certesa 90%
ÞUn raonament seria aplicar una base de regles a una base de fets per tal dobtenir noves conclusions.
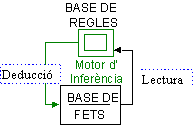
El raonament lexecuta el motor dinferència que sencarrega danar regla a regla inspeccionant si les pot aplicar de forma que es dedueixin nous fets a la base de fets.Hi ha dos tipus de motors dinferència,
- Forward Chaining : El que fa és cercar quines regles es poden aplicar amb la base de fets actual. Per això es va regla a regla inspeccionant les premisses per veure si cada regla és pot executar o disparar deduint-ne nous fets que van a engreixar la base de fets i que poden disparar altres regles. El motor satura de fer raonament quan no troba que cap regla es pugui disparar pel que no es poden deduir nous fets, i el procés de raonament sesgota amb tot lo deduïble.
Apa, vinga ! Lexemple consisteix en veure com es pot modelitzar el coneixement dun expert (un qualsevol com podem ser nosaltres, conductors habituals...) en cotxes quan al matí no consegueix engegar el seu cotxe.

Emprem els símbols següents per modelitzar el problema.
A = [Cotxe_No_sEngega]
B = [Possible_Problema_Elèctric]
C = [Bateria < 10 Volts]
D = [Bateria_Està_Baixa]
Exemple 1 : MOTOR FORWARD-CHAININGSigui aquesta la Base de Regles
Regla 1 : IF [Cotxe_No_sEngega]THEN [Possible_Problema_Elèctric] CERTAINTY 80%
Regla 2 : IF [Possible_Problema_Elèctric]
AND [Bateria < 10 Volts]
THEN [Bateria_Està_Baixa] CERTAINTY 45%
Que no és res més que dir :
Regla 1 : IF A THEN B CERTAINTY 80% Sigui aquesta la Base de Fets creada amb evidènciesRegla 2 : IF B AND C THEN D CERTAINTY 45%
A = [Cotxe_No_sEngega] Llavors aplicant Forward Chaining
Pas 1 : Inspeccionem la premissa de la Regla 2
Que vegem que les premisses cerquen fets com [Possible_Problema_Elèctric] que no hi són a la Base de Fets, i per tant aquesta regla no es pot disparar. Regla 2 : IF [Possible_Problema_Elèctric] AND [Bateria < 10 Volts]
THEN |Bateria_Està_Baixa| CERTAINTY 45%
Pas 2 : Inspeccionem ara la premissa de la Regla 1Com que tenim levidència que el cotxe no sengega (això es codifica a la Base de Fets com a [Cotxe_No_sEngega] llavors és possible disparar aqueixa regla i podem per tant deduir que hi ha [Possible_Problema_Elèctric].
Regla 1 : IF[Cotxe_No_sEngega]THEN [Possible_Problema_Elèctric] CERTAINTY 80%
Quan deduïm afegim un nou fet a la Base de Fets que queda com
A = [Cotxe_ No_ sEngega] B = [Possible_Problema_Elèctric]
Pas 3 : Inspeccionem les regles aplicables. Vegem que la regla 2 podria ser ara disparable.
Com que tenim levidència que hi ha un possible problema elèctric (això es codifica a la Base de Fets com a [Possible_Problema_Elèctric], vegem que només queda escorcollar laltra condició de la premissa de si [Bateria < 10 Volts]. Si aquesta evidència no hi existeix es pot demanar a lusuari una pregunta : Regla 2 : IF [Possible_Problema_Elèctric]AND [Bateria < 10 Volts]
THEN [Bateria_Està_Baixa] CERTAINTY 45%

Lusuari pot triar quina resposta, sí o no, o bé matitzar la resposta amb una certesa (de 0% a 100%). També pot decidir no contestar si no té cap idea. Si tenim en compte les restriccions de la supervisió on-line en cap cas el SE es pot aturar gaire estona esperant la resposta de lusuari. Però en aquest exemple deixem el temps que calgui fins que lusuari respongui qualque cosa, ja sigui sí, no o NS/NC (No en sap res / no contesta).imaginem que lusuari respon que SÍ. Aleshores el motor dinferència tindrà com a nova evidència que la tensió de la bateria (que es suposa quha mesurat lusuari humà) és més petita que 10 volts i la Base de Fets queda com així :
Ara sí que el motor dinferència pot disparar la Regla 2 deduint-se un nou fet que seria [Bateria_Està_Baixa], la conclusió final. A = [Cotxe_No_sEngega] B = [Possible_Problema_Elèctric]
C = [Bateria < 10 Volts]
Pas 4 : El motor dinferència satura doncs no hi ha més regles aplicables.
Exemple 2 : MOTOR BACKWARD-CHAINING
Sigui la mateixa Base de Regles de lexemple anterior
Regla 1 : IF [Cotxe_No_sEngega]THEN [Possible_Problema_Elèctric] CERTAINTY 80%
Regla 2 : IF [Possible_Problema_Elèctric]
AND [Bateria < 10 Volts]
THEN [Bateria_Està_Baixa] CERTAINTY 45%
Sigui la mateixa Base de Fets inicial de lexemple anteriorA = [Cotxe_No_sEngega] Llavors aplicant Backward ChainingPas 1 : Proposem una hipòtesi.- Aquesta és la gran diferència amb el motor forward chaining. Com que tenim levidència que el cotxe no sengega (això es codifica a la Base de Fets com a [Cotxe_No_sEngega] llavors lusuari humà té de proposar una hipòtesi, tal com "Que no serà un altra cop que falla la bateria perquè està baixa ?", que això no és res més que dir [Bateria_Està_Baixa]. Aquest fet es considera la hipòtesi i no forma part de la Base de Fets.
Pas 2 : Inspeccionem la conclusió de la Regla 1.
Regla 1 : IF [Cotxe_No_sEngega] Que vegem que la conclusió [Possible_Problema_Elèctric] no ens satisfà la hipòtesi de [Bateria_Està_Baixa], i per tant aquesta regla no es pot disparar.THEN [Possible_Problema_Elèctric] CERTAINTY 80%
Pas 3 : Inspeccionem ara les conclusions de la Regla 2Regla 2 : IF [Possible_Problema_Elèctric] I aquesta regla sí dedueix la hipòtesi. Ara que per poder disparar aqueixa regla hem de conseguir que la premissa es compleixi i per tant hem de cercar la regla que dedueixi [Possible_Problema_Elèctric].AND [Bateria < 10 Volts]
THEN |Bateria_Està_Baixa| CERTAINTY 45%
Pas 4 : Inspeccionem un altra cop la conclusió de la Regla 1.Regla 1 : IF [Cotxe_No_sEngega] On vegem que la conclusió [Possible_Problema_Elèctric] sí és deduïble en aquesta regla. Aleshores mirem si la premissa es pot complir. De fet, el [Cotxe_No_sEngega] ja hi és a la Base de Fets. Doncs aquesta regla és disparable. El fet de disparar-la vol dir deduir un nou fet que és el [Possible_Problema_Elèctric].THEN [Possible_Problema_Elèctric] CERTAINTY 80%
Quan deduïm afegim un nou fet a la Base de Fets que queda com Pas 5 : Inspeccionem les regles que són ara aplicables. Vegem que la regla 2 ja conte a la premissa el fet B (que ara és evidència) però encara li roman a la premissa el fet de [Bateria < 10 Volts] ? per ser finalment disparable.
A = [Cotxe_ No_ sEngega] B = [Possible_Problema_Elèctric]
Regla 2 : IF Com que [Bateria < 10 Volts] no és evidència aleshores es pot demanar a lusuari una pregunta :[Possible_Problema_Elèctric]AND [Bateria < 10 Volts]
THEN [Bateria_Està_Baixa] CERTAINTY 45%
imaginem que lusuari respon que SÍ. Aleshores el motor dinferència tindrà com a nova evidència que la tensió de la bateria (que es suposa quha mesurat lusuari humà) és més petita que 10 volts i la Base de Fets queda com així : Pas 6 : El motor dinferència satura doncs no hi ha més regles aplicables.Ara sí que el motor dinferència pot disparar la Regla 2 deduint-se la hipòtesi que era [Bateria_Està_Baixa] ?, i per tant queda demostrat que la hipòtesi era certa, i la resposta a loperador humà. A = [Cotxe_No_sEngega] B = [Possible_Problema_Elèctric]
C = [Bateria < 10 Volts]
Tornant al Principi : una aplicació dels Sistemes Experts. Per exemple, control de processos.
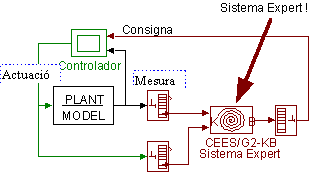
Aquesta és una arquitectura de control reconfigurable desenvolupada per un SE that obtains information from inputs (Action) and outputs (Measure) of the controlled plant (in development stages this is a simulated PLANT MODEL). The ES contains rules that use object fields such as the recent history to make signal analysis and diagnostics, ranges to know which are the qualitative states of the signals and some knowledge about trends to decide about firing alarms. This information is accessible immediately from the object structure that is created by "Mesura" blocks, see the following picture. Ranges are numerical limits of zones that allows a rough qualification of each signal. Initially, this is a user defined parameter although access methods can change its values dynamically. This information is used around all the environment of supervision by means of object-variables.
Variable que conté informació com la qualificació i la finestra temporal, on hi són els històrics de levolució dinàmica del senyal mesurat.
The ES accepts the measured information that has been converted into objects as a tanklevel object that contains enough knowledge to develop diagnostics and guide actions on set points. For instance, see the following rule written in CEES code:
Certainty 0.6
Description "The tank level is Low Þ Alarm 078 and setpoint to high values to avoid danger"
If tanklevel->lower (tanklevel->low)
And
tanklevel->downs_in_interval()
Then
deduce (DIAGNOSTIC, ALARM078);
setsetpoint (tanklevel->high); // Security Value of setpoint
EndIf
EndRule
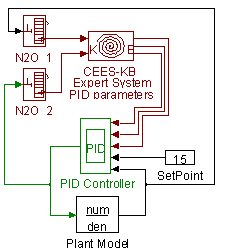
Expert Tuning of PID parameters
It is possible to conceive a solution that changes range values for qualification, and other information from objects so that heuristics advises to change. Limits for alarms embedded in object-variables could be changed according ES rules. Several features of objects could be modified using a generic structure as the following figure shows.
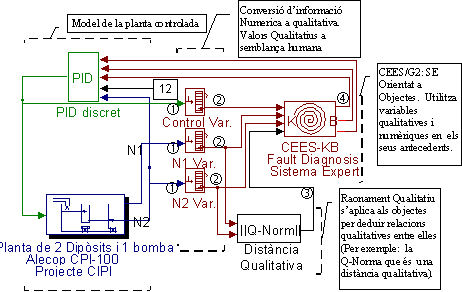
4. Què és G2 ?
Programmation (Programació)
G2-Simulator (El simulador de G2)
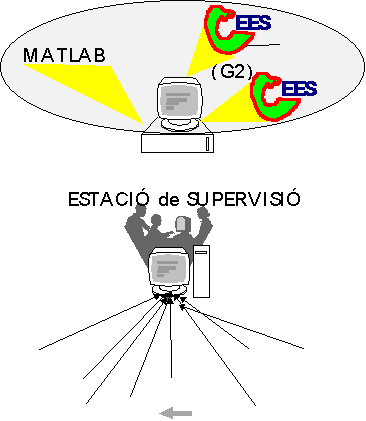
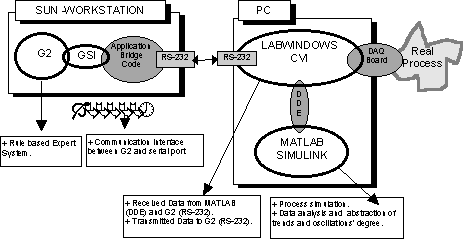
La següent figura representa una implementació tecnològica realitzable on es representa el control distribuit col·locant el SE en una SUN station a una distància duns 1500m de lestació de monitorització en la planta. Mitjançant GSI es connecta via TCP/IP a lestació SUN remota i aquesta via RS232 cap a larquitectura PC que du implementades les eines dabstracció qualitativa i la monitorització mitjançant LabWindows.
5. Com funciona el motor a TR de G2 ?The Inference Engine
TR vol dir Temps Real
The G2 real-time inference engine reasons about the current state of the application, and communicates with the end-user or initiates other activity based upon what it has inferred. The inference engine operates on the following sources of information:The inference engine can:The knowledge contained in the knowledge base Simulated values Values received from sensors and other external sources Backward chaining and forward chaining are common to most inference engines.Scan key rules at rates indicated in each rule Focus on key objects or classes by invoking associated rules Invoke categories of rules for a particular class Invoke rules based on an event Backward chain to other rules to find values Forward chain to rules when values are found Respond to events from you, the simulator, or external data servers Launch procedures for sequential control Scanning, focusing, and invoking are additional, essential techniques for working with real-time applications.
| In this chapter are described in the following order |
| Scanning Rules |
| Focusing on Rules |
| Invoking Rules |
| Wakeup Rules |
| Chaining to Rules |
| Backward Chaining |
| Forward Chaining |
| Data Seeking |
| Applying Generic Rules |
| Prioritising Rules |
| Completing Rules |
| Variable Failure |
| Simultaneous and Sequential Execution of Actions |
| The Scheduler |
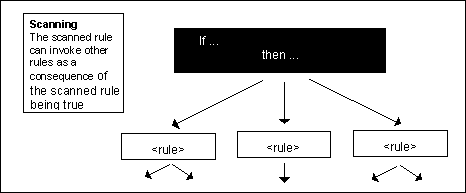
Scanning Rules
This inference engine can repeatedly a rule at regular time intervals; this is called scanning. The time interval between invocations is called the scan interval for the rule. The time interval between invocations is called the scan interval for the rule. You set a rules scan interval in its scan interval attribute. Thus, if you want G2 to check the temperature of tank-4 every five minutes, you can assign a Scan interval of five minutes to the following rule.
If a generic rule has a scan interval, the inference engine invokes each instance of the rule every scan interval. Thus if you have a rule that applies to any terminal, connected to any modem, the inference engine invokes that rule for each such terminal once every scan interval.
Focusing on Rules
When the inference engine executes a focus action on an object, it invokes all rules that have the object as a Focal object, or that have its class or one of its superior classes as a Focal class. For example, suppose that G2 executes the following action:focus on terminal-1
To execute this command, G2 invokes all rules that have terminal-l as a Focal object or one of its superior classes as a Focal class. G2 then executes each of those rules for terminal-l. For example, if the following rule has terminal-l as a focal object, or terminal or computer-equipment as a focal class, G2 invokes it for terminal-l:
if any terminal is on then inform the operator that "[ the name of the terminal] is on '
Invoking Rules
When the inference engine executes an invoke action on a rule category, it invokes all rules in that category. An example is:invoke safety rules
This tells the interference engine to invoke all rules that have safety as a Focal category. The inference engine invokes such rules universally for every object referred to in the rule. For example, if the following is a safety rule, the inference engine invokes it for every tank in the application:
The following is another form of the invoke action: for any tank if the tank is hot then inform the operator that "[the name of the tank] is hot." and focus on the tank When the inference engine executes this action, it invokes all the rules that have safety as a Category and tank-4 as a Focal object or one of its superior classes Focal class. It invokes each such rule just for tank-4. invoke safety rules for tank-4
Wakeup Rules
When a variable that has been waiting for a value receives a value, the inference engine wakes up the rule that was waiting for the value of the variable. An example is:
Until the data server returns a temperature reading, the inference engine does other things. When it receives a temperature reading from the data server, it re-invokes the rule. This is called wakeup.
After a specified amount of time has passed, the inference engine will not wakeup a rule that has been waiting for a value. The amount of time that the inference engine allows is determined by either the rule's timeout-for-rule-completion parameter or by the Timeout-for-inference-completion attribute in the inference-engine-parameters system parameter.
Chaining to Rules
The inference engine in G2 uses two types of chaining to invoke rules: backward chaining and forward chaining. Both types are explained in this section.Backward Chaining
If the value of a variable is not given by a sensor or by a formula, then the inference engine uses backward chaining to infer the value from rules that conclude a value for the variable. An example is:
To evaluate the antecedent of this rule, the inference engine can invoke any rule (that is invocable via backward chaining) that concludes a value for valve-is-broken. For example, the inference engine can backward chain to the following rule: it valve-is-broken of valve-1 then focus on repair rules for valve-1 Then, to evaluate the antecedent of this rule, the inference engine many need to backward chain to rules that provide values for valve-is-closed and tank-is-overflowing. The interference engine continues to backward chain until it can evaluate all the necessary conditions in the antecedents of each rule. for any valve
if valve-is-closed of the valve and tank-is-overflowing of the tank connected to the valve
then conclude that valve-is-broken of the valve
To keep rules from being invoked unexpectedly, you can set a rule to be invocable or not invocable via backward chaining or data seeking. You set these characteristics for
a rule in the Options attribute for the rule.
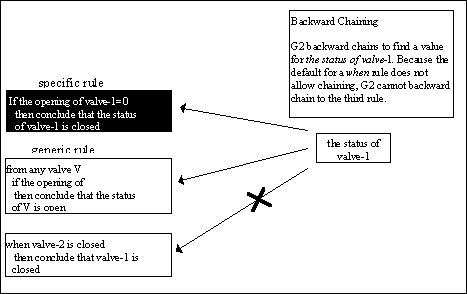
You can also indicate in a variable's attribute table whether the inference engine should backward chain for the value of a variable with a depth first search or a breadth first search. The following sections describe each of these two chaining methods.
Depth First Backward Chaining
In a depth first search, the inference engine collects the rules that can provide a value for the variable and invokes them according to precedence. (Depth first precedence is explained below.)
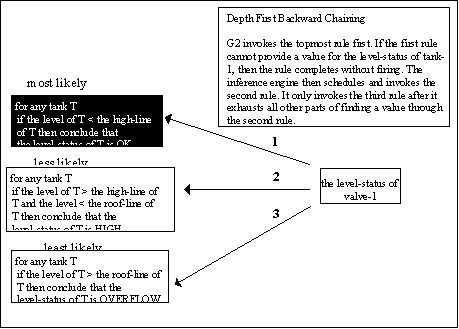
Before rules are invoked for depth first backward chaining, they are sorted by precedence as given by their Depth-first-backward-chaining-precedence attribute. Rules with the highest (smallest numbered) precedence are invoked first. The inference engine invokes lower precedence rules after the higher precedence rules have completed without supplying a value. For example, the rules above could have the precedence indicated on the arrows. G2 will wait for a rule to complete before moving on to the next rule, even if it takes a while because the first rule is waiting for something that is idle. Depth first chaining, therefore, allows you to determine the exact order in which rules will be tried. In this case, the rules have been assigned precedence according to the likelihood of their finding a result: the most likely rule has the highest precedence, the least likely the lowest precedence, and so on.
Breadth First Backward Chaining
Consider a similar situation to that described above, but assume that the inference engine is to find a value for the direction of robot-arm-l with a breadth first search. The following diagram shows the inference engine would execute a breadth first search for the value it needs.
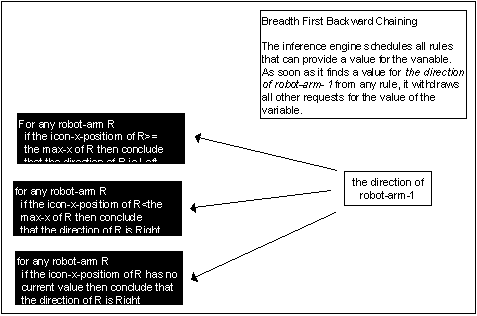
This eliminates needless work for the inference engine.
Forward Chaining
The inference engine forward chaining to invoke a rule when at least one of the conditions in its antecedent is satisfied by another rule. For example, if an if rule concludes that temperature-is-too-hot, the inference engine can invoke the following rule, which has temperature-is-too-hot as a condition in its antecedent
This activity, called forward chaining, is a form of deductive reasoning- through forward chaining, the inference engine can use rules to draw conclusions from one or more others. Similarly, the inference engine can use forward chaining to initiate actions from conclusions drawn in other rules. if temperature-is-too-hot of tank-1 and... then conclude that tank is overflowing The following figure shows another example of how forward chaining.
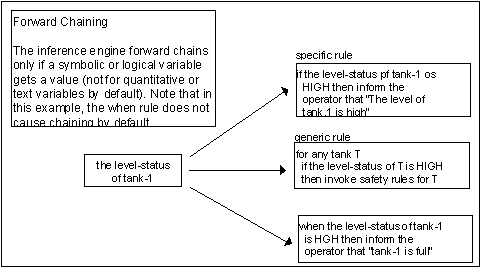
Note that you can edit a variable's Options attribute to change its default behavior.
Thus, for example, you can change the behavior of a quentitative variable so that the inference engine forward chains whenever it gets a value.
A rule's Options attribute controls whether it is invocable via forward chaining. For example, the inference engine does not forward chain to whenever rules; a whenever rule's options are always set so that the rule cannot be invoked as a result of forward chaining. However, though you cannot forward chain to a whenever rule, you can potentially forward chain from one. In that case, forward chaining can occur when a whenever rule concludes a value for a variable (if that variable permits forward chaining). All other rules can be set to be invocable or not invocable via forward chaining.
In the case of when rules, invocation occurs when the category is invoked, as a result of a scan interval, as a result of a focus, or via backward chaining. A rule can execute more than once per second. As a result, a rule can potentially forward chain to itself.
For example, the following rule chains to itself many times within a second until x=20:
This can be useful in constructing loops, but such loops must have some way of ending; for example, the rule above loops only until x = 20 and then stops. In contrast, the following rule can chain to itself repeated without stopping, thereby causing a heavy load for G2: if (x>0 and x<=19) then conclude that x = x + 1
Please note that this looping will not happen when forward chaining is turned off for this rule (in the rule's Options attribute). Take care not to construct rules (or sets of rules) that will cycle repeatedly without a logical end. if x > 0 then conclude that x = x + 1
Data Seeking
When G2 needs a value for a variable, it looks at the last recorded value of the variable to see if it has expired. If it has not expired, G2 uses that value. If the value has expired, G2 checks the variable's Data server attribute to determine whether the variable gets its values from the inference engine, the G2 simulator, or some other data server. It then attempts to get a value from the specified data server; this attempt is called data seeking.Note that data seeking applies only to the G2 values of variables. A parameter always has a value, so G2 never needs to seek a value for a parameter. Similarly, if a variable has a simulated value as well as a G2 value, the simulator automatically finds a new simulated value for that variable each simulation cycle, so data seeking does not apply to simulated values. Throughout the rest of this section, the phrase "the value of the variable" refers to the G2 value of a variable.
When G2 Seeks Data
If no part of G2 needs the value of a variable, then G2 may not automatically seek a new value when an old value of that variable expires. G2 begins data seeking only when something requires a current value for a variable.
Causes of Data Seeking1. A variable has an update interval
2. A display that reters to the variable has an update interval
3. A rule references bÿthe variable
4. A local name declaration, a collect data statement, or a wait until statement in a procedure references the variable
5. An update action references the variable
Note that, if a variable has a current value, G2 does not need to seek a new value. G2 seeks a value for a variable when something needs a value for the variable and the variable's value has expired. Thus, G2 may not need to search for a value of a variable every time the variable's value is requested.
How G2 Seeks Data
When G2 needs a value for a variable and the last recorded value of the variable has expired, G2 checks the variable's Data server attribute to determine whether the variable gets its values from the inference engine, the G2 simulator, or some other data server.It gets a value for the variable from the appropriate data server, as follows:
1. If the variable gets its values from the inference engine, G2 does the following:
2. If the variable gets its values from the G2 simulator, G2 takes the simulated value of the variable. The G2 simulator computes the simulated value each simulation cycle, based an the following:If the variable has a specific formula in its Formula attribute, it uses that formula to compute a value for the variable. Otherwise, if there is a generic formula that applies to the variable, G2 uses that formula to compute a value. Otherwise, if the variable allows backward chaining, G2 backward chains to other rules to find a value for the variable. Otherwise, G2 fails to get a value for the variable. 3. If the variable gets its values from another data server, G2 requests a value from that data server. G2 then performs other tasks until it receives the value. If G2 does not receive the requested value within the time specified in the Timeout-for-variables parameter, then it fails to find a value for the variable.If there is a specific simulation formula for the variable in the variable's simulation subtable, G2 uses that formula to compute values for the variable. Otherwise, if there is a generic simulation formula that applies to the variable, G2 uses that formula to compute a value. Otherwise, G2 fails to find a value for the variable.
When Data Seeking Fails
When a variable fails to receive a value, the variable is said to have failed. A variable fails if G2 makes a request for the value of the variable and one of the following is true:
If, on the other hand, G2 has withdrawn all requests for the value of the variable before the timeout expires, or before it has tried all avenues for finding the value of the variable, then the variable is not considered failed.The variable does not receive a value within the timeout for variables time period. G2 has attempted all possible avenues for determining the value and these have failed . When a variable fails, G2 does two things:
As long as there are pending requests for the variable's value, G2 retries the variable once every retry period. When there are no more requests for the value of the variable, G2 stops retrying the variable, but the variable is still considered failed. A failed variable remains failed until it receives a value.It invokes any whenever rules that check for that variable's failure. This means that G2 invokes any rules that have the form whenever <variable> fails to receive a value ..., where <variable> is the failed variable. It schedules a task to retry the variable, that is, to try again to get a value for the variable. You can use failed variable behaviour in your knowledge base. If you know a certain variable is likely to fail to receive a value, then you can construct whenever rules that fire when the variable fails. These rules can give the variable some value that indicates failure, and other things in the knowledge base can react to that failure value.
Event-Driven Activity
The inference engine can invoke a whenever rule whenever a variable receives a valueexample, each time a sensor variable gets an unrequested value from a data server), or whenever a variable fails to receive a value. Thus, G2 can respond to events as the occur in the system that it monitoring.
Causes of Event-Based Reasoning1. variable or parameter receives value - forward chaining
2. variable fails to receive a value
3. item is moved by G2
4. item is moved by a user
5. relation is established
6. relation ceases to be
Activating and Deactivating SubworkspacesIn the consequent of a rule, you can tell the inference engine to activate any object that has the capability activatable subworkspace. When the inference engine activates the object, it activates the object's subworkspace and the rules and other items on that subworkspace. It all also executes all of the initial rules that are on the subworkspace
This enables you to store information on subworkspaces, then essentially turn it on and off as it is needed or not needed.
You can use the activate and deactivate actions to specify which objects to activate or deactivate at any given time. Refer to "Actions'' on page 5 for more information.
Setting Simulated ValuesThe inference engine can use the set action to change the simulated value of a variable.
This allows the inference engine to update simulated values based on values received by sensors, and thus maintain a more accurate simulation. Note, however, that this is effective only if the variable is a state variable. If, instead, the simulated variable is a dependent variable, then the value that you set is lost as soon as the simulator calculates a new value for the variable.
To allow the inference engine to set a simulated value that the simulator then uses when it re-evaluates the variable, you must make the variable a state variable, a variable that depends on its own previous value. Refer to "Variables" on page 459 for more information.
Applying Generic Rules
This section explains what the inference engine does when it invokes a generic rule. What the inference engine does depends upon whether the rule is invoked with or without a focal object. An example is:
if V1 is broken then inform the operator
that "[V1] is broken"
and conclude that is-maintenance-required
is true
When the inference engine invokes
the above rule with a focal object (as a result of executing a command
such
as focus on valve-l, for example), then it applies the rule to just
one valve -- the one that it is focusing on.
Now look at a more complicated rule for the valves and tanks on the schematic in the next figure:
for any tank T
any valve V1 connected to T
if V1 is broken...
The result of applying a rule like
this without a focal object is that the inference engine does the following:
In a configuration like that in
the illustration above, the rule applies to four cases: (tank-l, valve-l),
(tank-l, valve-2), (tank-2, valve-2), and (tank-2, valve-3).
If the inference engine invokes the same rule with a tank as a focal object, tank-2 for example, then the inference engine applies the rule to only those cases that concern tank-2. In this case. the rule would be applied to (tank-2, valve-2) and to (valve-3).
For each of these cases the inference engine checks if the valve is broken, and fires the rule it is.
Prioritising Rules
When the inference engine executes tasks for a rule can be affected by the Rule priority attribute for that rule. A rule's Rule priority controls the priority at which tasks for the rule are scheduled. In the unusual case that G2 is overloaded, the inference engine executes higher priority tasks first; it executes lower priority tasks as soon as possible.The inference engine gets a current task queue from the scheduler, listing the tasks to be done in a given second. Within this queue, tasks are sorted according to their priorities; that is, tasks of priority 1 are scheduled first, priority 2 second, and so on. Each time a task is completed, the inference engine starts executing the next highest task in the list. If a task with priority 1 comes in while the inference engine is working on a priority 2 task, then after the priority 2 task completes the inference engine starts executing the priority 1 task.
Scheduling tasks by priority becomes important in the unusual case when G2 is working at maximum capacity. Lowest priority tasks may be deferred until the next second. You should use priorities, then, to identify what tasks may be deferred, and how important a particular task is. Please see the section on rule priorities for more information.
Completing Rules
Rule completion is an important concept for understanding how G2 and the inference engine work. To understand how a rule completes, though, you need to understand what happens when the inference engine invokes a rule.When a rule is invoked, the scheduler schedules it on the task queue, the queue of tasks scheduled to execute as soon as there is computational time. At the same time, the scheduler schedules another task that will force the rule to complete if it has not done so within a timeout period. (Rule timeouts were explained in more detail earlier in this chapter.) The inference engine begins executing the rule when it reaches the front of the task queue.
G2 begins executing a rule by attempting to evaluate the logical expression in the antecedent of the rule. One of three things happens:
One or more variables in the antecedent does not have a current value. In this case, the inference engine puts the rule to sleep and sets wakeups on the variables. If any of the variables receives a value, the rule wakes up and tries again to complete. The antecedent of the rule evaluates to false, and the rule completes without firing. The antecedent of the rule evaluates to true. When this happens, the way the inference engine executes the consequent of the rule (that is, the way the rule fires) depends on whether you indicated in the rule that the actions in the consequent should be executed simultaneously or in order. The two cases are as follows:
In the unusual case when
the timeout happens before the rule finishes execution, the rule has one
last chance to run, and then it completes, whether or not it was able to
fire (that is, execute its consequent).
Variable Failure
When a variable fails to receive a value, it is said to have failed. A variable fails if the inference engine makes a request for the value of the variable and one of the following is true:
If, on the other hand, the inference
engine has withdrawn all requests for the value of the variable before
the timeout expires, or before it has tried all avenues for finding the
value of the variable, then the variable is not considered failed.
When a variable fails, the inference engine does two things:
It invokes any rules that check for
that variable's failure. This means that the Inference engine invokes any
rules that have the form whenever <variable> fails to receive a value...,
where <variable> is failed variable.
As long as there are pending requests
for the variable's value, the inference engine retries the variable once
every retry period. When there are no more requests for the value of the
variable, the inference engine stops retrying the variable, but the variable
is still considered failed. A failed variable remains failed until it receives
a value.
Simultaneous and Sequential Execution of Actions
By default, the inference engine performs the actions in a rule simultaneously. A variable has the same value throughout a simultaneous rule, even if an action in the rule changes its value; all actions are seen to take place at the same time, and none before the rule completes Consider the following rule:
then conclude that x = x + 1 and conclude that x = x + 1
In this case, the value of x is
incremented only once when the rule completes. lf the rule is interrupted
while it is executing, then when it is reawakened it starts again from
the beginning, checking the antecedent and then proceeding through the
actions.
Alternatively, the inference engine can execute actions sequentially, by using the in order syntax. An example is:
if <condition>
then in order conclude that x = x + 1 and conclude that x = x + 1
If the antecedent is true, each action in the consequence completes in sequence. Since actions are executed in order x is incremented twice when the above rule completes. If the rule is interrupted for any reason -- if it has to wait for the value of x, for example -- then on reawakening it resumes where it left off.
Please note that in in order (sequential) processing, there is no guarantee that processing will not be interleaved. That is, between two actions in a consequent it is possible that another action might be executed as a result of some other process. In the above example, the value of x could change between the two times it is incremented. All that is guaranteed is that the actions in the consequent execute in order. With simultaneous processing, however, you are guaranteed that variables maintain their values throughout processing, and that no action will occur until the rule completes.
The Scheduler
The scheduler is the process that directs all other processing in G2. While a user never interacts with it directly, it controls all of the activity that the user does see, as well as the activity that runs in the background. The scheduler determines the order in which processing takes place, interfaces with data servers and users, executes processes, and communicates with other processes over networks.The scheduler works with tasks, which are the smallest units of activity that G2 does. A single action, for example, might be comprised of a number of tasks. Tasks are very small, that is, they take little time; as a result, the scheduler can shuffle them easily without affecting the way the knowledge base operates as a whole. The scheduler takes rules and other activities in the running of the knowledge base and divides them into their component tasks, then schedules each task to take place at the appropriate time.
The scheduler schedules and performs these tasks in clock-ticks. The clock-tick is the basic unit of time within G2. It is the period of time that G2 needs to process the tasks that are scheduled for a particular clock-tick. This length of time is partially determined by the value of the Scheduler-mode attribute in the timing-parameters system table. The approximate duration of a clock-tick is given m the table below.
In some unusual situations, G2 may be overloaded and unable to complete all of the tasks scheduled for a particular clock-tick during that clock-tick. As a result, the scheduler may need to defer some tasks until the next second. Tasks are therefore given priorities that indicate their relative importance. A low priority means that a task may be deferred temporarily if necessary. The scheduler uses priorities in scheduling which tasks will be completed in a given clock-Tick and what order they will be completed in. Scheduler mode Approximate Duration of a Clock-Tick real-time One second
simulated-time One second or the length of time required to complete all the tasks scheduled for that clock-tick, whichever is greater
as-fast-as-possible The length of time required to complete all asks scheduled for that clock-tick (this time may be less than one second)
The remaining sections in this chapter explain what the scheduler does and how the scheduler uses task priorities.
What the Scheduler Does
The scheduler has a set of things to do in each clock-tick and it tries to get them done in this time. Within a clock-tick, the scheduler does the following:
If it did not do anything in the current clock-tick, the scheduler sleeps for 40 milliseconds, then goes to step 1 as above.Checks if it is time to tick -- If it is, the scheduler ticks the clock and moves on to the next step. Schedules waiting tasks -- The scheduler schedules tasks that should be performed within the current clock-tick. The schedule that it creates IS called the current task queue. Services data servers -- The scheduler sends to and receives from any available data servers. Each data server has at most 0.1 seconds to perform its processing. For any servers that could not complete sending in this time, the scheduler schedules a task to try to complete transmission at the priority that is indicated by the Priority-of-data-service attribute in the data-server-parameters system table. Performs tasks -- The scheduler takes the current task queue and attempts to execute as many tasks as possible. Any that are not finished after 0.2 seconds are deferred to later in the current clock-tick or to the next clock-tick. Services network packets -- The scheduler sends and receives messages over the network It does this for up to 0.2 seconds. Services user interfaces -- The scheduler receives input and sends output to the user interfaces of all users logged in to this G2. This includes any Telewindows users. Prepares to loop - The scheduler checks to see if it was active in this clock-tick. If it was (if it received any input, completed any tasks, and so on) it goes back to step to step 1 to see if it is time to tick. lf it is not time to tick, the scheduler moves to step 3 to finish anything it missed earlier. If it is time to tick, the scheduler ticks the clock and continues as usual. How Priorities Affect Scheduling
Every task has an associated priority that indicates the relative importance of the task, and that the scheduler can use in the unusual case that G2 is overloaded. When the scheduler creates the current task queue (the list of tasks that are to be performed in the current clock-tick) it sorts the tasks by priority; that is, it schedules tasks of priority 1 first, priority 2 second, and so on. If the scheduler is unable to perform all the tasks in the queue within the time allotted (for example, if G2 is working at maximum capacity), it defers the remaining tasks to the next clock-tick. Thus, highest priority tasks have the greatest chance of being performed right away.
Some standard tasks in G2 have set priorities that you cannot change, while the priorities of others are controlled by attributes. For example, initially always have a priority of one, which cannot be changed; other rules have a default priority of six, which is set for each rule in the rule's Rule priority attribute.
The fact that a rule has a high priority does not guarantee that it will be executed before another rule with a low priority. A task for the high priority rule may require a value for a variable which is not available, and while the task is waiting for the value the tasks for the low priority rule may all be performed. Therefore, you should not attempt to use priorities to control the order of processing. Instead, you should use priorities to identify what tasks may be deferred and the importance of a particular task.
Rule Priorities
Every rule has a Rule-priority attribute that determines the priority at which tasks for the rule are scheduled. This attribute may take a value from one to ten, with one indicating highest priority.
Rule priorities propagate through backward chaining. Also, if two rules with different priorities backward chain to the same rule, the third rule is scheduled with the higher (lower numbered) priority. For example, if a rule r1 with priority 3 and a rule r2 with priority 5 both backward chain to rule r3 with priority 8, then r3 is scheduled with priority 3. If r1 is then cancelled, r3 is not rescheduled with priority 5; it retains its priority 3 status. Please note also that priorities do not propagate through forward chaining, nor as a result of focus or invoke.
Action Priorities
Action buttons have an attribute called Action- priority, Which determines the priority at which tasks for the action of the action button are scheduled. This is very similar to the Rule-priority attribute for rules. You can specify an integer from one to ten, with one indicating highest priority.
Default Task Priorities
Many common tasks have priorities set by default. Some of these defaults are as follows:
Unless otherwise noted, you cannot change these defaults. Task Default Priority Execute initially rules Initially rules have a priority of 1. You cannot change this priority.
Update buttons When the value of a variable changes and is reflected in an operator control, the task for updating the operator control has priority 2.
Remove or unhighlight Tasks to remove or unhighlight messages to the messages operator have priority 2.
Complete data service When G2 cannot receive all of the values from a data server in the time that is allowed, the scheduler schedules a task to finish reading that data. This task has priority 4. You can change this priority with the Priority of continued data service option in the data- server-parameters.
Update displays (readout Updating screen displays consists of two parts. First, tables, meters, dials, graphs, the value of the display is found; second, the screen charts, and freeform-tables) display is changed. The tasks for such updates have a default priority of 2. You can override this in an i ndividual display's attribute table.
Update variable values The values of variables are found through backward chaining and other data seeking, as specified by the default update interval of the variable. It has priority 4.
Invoke general rules Rules have a default priority of 6. You can set an individual rule's priority in its attribute table.
Reply to outside requests for Tasks to send data have priority 6.
data from G2.
Detect variable failure, and The tasks to detect when a variable has failed and to retry variables retry failed variables have priority 8.
Though this is a generic rule for main-frames, G2 does not invoke the rule when focusing on a particular main-frame, because the rule has neither main-frame as a focal object nor the mail-frame class as a focal class, nor one of its superior classes as a focal class.
A rule can have any number of focal objects or focal classes.
The Categories Attribute
By categorising rules, you can use the invoke action to invoke all rules of that category or to invoke all rules of that category for a particular object. For example, you can write. a number of safety rules, then enter safety as the value in the Categories attribute of each rule Finally, you can direct G2 to invoke the rules, or to invoke the rules for a particular object:
...invoke safety rules
...invoke safety rules for tank-1
In the first case. G2 invokes all safety rules. In the second case, G2 invokes safety rules for tank-l. Refer to "Invoke" on page 22 for more information.
You can specify any symbol (except G2 reserved words) as a category: safety, economy, quality, emergency, and so on. Note that a rule can belong to more than one category at a time. For example, the same rule could be both a safety rule and an emergency rule.
The Rule-Priority Attribute
The Rule-priority attribute takes as a value an integer value from one to ten, with one representing highest priority. You use this attribute to control the priority at which tasks for the rule are scheduled. In the unusual case that your system is overloaded, G2 will execute higher priority tasks first, but will execute lower priority tasks as soon as possible.
Priorities are used only to specify what tasks can wait if the inference engine is overloaded, not to control the order of actions. Giving a rule a high priority does not guarantee that it will be completed before a particular low-priority rule. The high priority rule might need to wait while data seeking is performed for values it needs; during the time that it is idle, a low-priority rule could complete.
Priorities propagate through backward chaining. Also, if two rules with different priorities backward chain to the same rule, the third rule is scheduled with the higher prior. For example, if a rule r1 with priority 3 and a rule r2 with priority 5 both backward chain to rule r3 with priority 8, then r3 is scheduled with priori 3. If r1 is then cancelled, r3 is not rescheduled with priori 5; it retains its priori 3 status. Note that priorities do not propagate through forward chaining, nor as a result of a focus or invoke action.
The Depth-First-Backward-Chaining-Precedence Attribute
The Depth-first-backward-chaining-precedence attribute takes a positive integer value. The highest precedence (and default value) is one. You use precedence to set explicitly the order in which G2 looks at rules. For example, if a variable backward chains to three rules, you can give them different precedence to force G2 to look at them in a particular order. You might give the best (or most likely) rule highest precedence, the next best the next highest precedence, and so on.
Precedence affects only depth-first backward chaining; it does not affect breadth-first chaining.
Note that precedence differs from rule priority: rule priorities determine which tasks can wait if G2 is overloaded, while precedence determine the order of rule invocation.
Before rules are invoked for backward chaining, they are sorted by precedence as given by their Depth-first-backward-chaining-precedence attribute. Rules with the highest precedence (smallest integer) are invoked first.
In depth-first chaining, G2 invokes lower precedence rules after the higher precedence rules have completed without supplying a value. For example, if a rule r2 has a higher precedence than rules r1 or r3, it would have to fail to find a value before either r1 or r3 is invoked. G2 will wait for a rule to complete before moving on to the next rule, even if the first rule is waiting for something that is idle. Depth-first chaining, therefore, allows you to determine the exact order in which rules are invoked.
The Timeout-For-Rule-Completion Attribute
The Timeout-for-rule-completion attribute indicates how long G2 may try to evaluate the antecedent of a rule before giving up and completing the rule, without evaluating its consequent. The possible values are:
If the time interval (whether specified or default) expires before G2 can complete evaluation of the antecedent, the rule completes, but is considered to have failed. When the timeout interval for a rule arrives, G2 attempts to evaluate the rule a final time. If G2 cannot evaluate the rule on this final pass, G2 completes the evaluation without executing any actions in its consequent. <interval> G2 tries to evaluate the antecedent within the specified time interval before giving up. None G2 evaluates the rule's antecedent until G2 either determines that the antecedent is false, or it can proceed to evaluation of the rule's consequent. In other words there is no timeout, so the rule never times out.
use default G2 tries to evaluate the antecedent within the default time interval, which is specified in the Inference-engine-parameters system table.
Invoking and Computing Rules
G2 can invoke rules in the following ways
| Method of Invocation | Rules Invoked | Description |
| Activating
a
Subworkspace |
|
When G2 activates an object, it activates the objects subworkspace and the rules and other items on that subworkspace. It also invokes all of the initially rules that are on the subworkspace. |
| Data Seeking
(Backward Chaining) |
|
G2 invokes a rule that concludes a value for a variable when data seeking is begun for variables that use the inference engine as their data server. You can indicate in a variable's Options attribute whether the inference engine should perform data , seeking (backward chaining) for the value of , a variable with a depth-first search or a . breadth-first search. A rule's Options I attribute controls whether it is invocable through backward chaining. Refer to "Data Seeking" on page 230 for more information. |
| Event-Driven Activity |
|
G2 invokes a rule whenever an event mentioned in the antecedent occurs. |
| Event Updating
(Forward Chaining) |
|
G2 invokes a rule when a value or the expiration of a value used by that rule changes. This is a form of event updating called forward chaining. A rule's actions attribute controls whether it is invocable through forward chaining. Refer to "Event-Driven Activity" on page 232 for more information. |
| Focusing |
|
G2 invokes rules with a specified focal object or focal class when it executes a focus action. |
| Invoking |
|
G2 invokes rules with a specified category when it executes an invoke action. |
| Scanning |
|
G2 invokes a rule at regular intervals. The length of the time interval is controlled by the rule's Scan-interval attribute. If a generic rule has a scan interval, G2 invokes each instance of the rule every scan interval. |
| Method of Invocation | Rules Invoked | Description |
| Wakeup |
|
G2 resumes execution of a previously invoked rule when the rule is awakened by a variable that has been waiting for a value, and the value is referred to in the rule. |
Scheduling and Completing Rules
When a rule is invoked, G2 schedules invocations of the rule on the task queue, the queue of tasks scheduled to execute as soon as computational time is available. At the same time, G2 schedules another task that will force the rule invocation to complete if it has not done so within a timeout period. G2 begins execution of each rule invocation when it reaches the top of the task queue.The invocations of a rule are scheduled by generating one invocation for each valid set of values for the generic reference in the rule. (The generic references of a rule have the word any within them.) If a rule has no generic references, then one rule invocation will be scheduled.
If a generic rule is invoked by scan intervals or by invocations with no focal object, an invocation of the rule is scheduled for each valid set of values for each of the rule's generic references. Consider the following rule:
for any valve
for any tank connected to the valve
The generic references in this rule are for any valve and for any tank connected to the valve. Invocations of this rule are scheduled for any valve connected to any tank in the knowledge base. For example, if your knowledge base has four valves, and each valve is connected to two tanks, then a total of eight invocations are scheduled for this rule. if the temperature of the valve > the temperature of the tank then conclude that the tank is thermally-downstream-of the valve
If a generic rule is invoked with a focus action, then the local name of its generic reference is given the object of the focus action as its value. An invocation is made for each valid set of resulting generic reference values. Consider the following focus action:
...focus on valve-1
An invocation of the rule stated above is scheduled for any tank connected to valve-l in the knowledge base, and it results from the focus action focus on valve-l. valve is the local name of the generic reference that corresponds to the rule, and the object that this generic reference is given to focus on is valve-l. If there are two tanks connected to valve-l, two rule invocations are scheduled as a result of this focus action.
G2 begins executing a rule invocation by attempting to evaluate the logical expression in the antecedent of the rule. When G2 evaluates the antecedent, one of three possible results can occur:
One or more variables in the antecedent does not have a current value. In this case, G2 puts the rule invocation to sleep and sets a wake-up flag on each variable that needs a value. If any of the variables receives a value, the rule invocation wakes up.
And tries again to complete evaluation of the antecedent.
In the unusual case where the time-out occurs before the rule finishes execution, the rule has one last chance to be evaluated, then it completes, regardless of whether G2 was able to execute the consequent.The antecedent of the rule evaluates to false, and the rule invocation completes without evaluating the consequent. The antecedent of the rule evaluates to true. G2 executes actions of the consequent in two ways: sequential execution of actions, or simultaneous execution of actions. Sequential Execution of Actions in the Consequent
A rule with the phrase in order after the word then in the consequent causes G2 to execute the actions in the consequent sequentially. G2 evaluates and executes each action in order. If any of the actions cannot be evaluated immediately, G2 puts the rule to sleep and sets a wakeup flag on each variable that does not have a value. If any of these variables receives a value, the rule wakes up and begins evaluation again, starting where it left with the action that could not be evaluated immediately)
Note that G2 does not re-evaluate the antecedent.
If the rule times out while it is waiting for a variable, it wakes up and goes into a final execution state. In this state, the inference engine tries to execute any inform actions without knowing the values of all variables; that is, it prints messages with asterisks substituted for variable values. The rule then completes and discards any actions that could not be executed.
Simultaneous Execution of Actions in the Consequent
If the phrase in order is not present in the consequent, G2 executes the actions simultaneously. G2 evaluates the expressions in each action of the consequent. If all of the expressions and references in the actions evaluate, then the actions are all executed at once. If any expression does not evaluate because variables do not have values, then G2 puts the rule to sleep and sets wakeup flags on the variables. When any of these variables receive values, the rule wakes up and G2 tries to evaluate the rule again. At that point, G2 re-evaluates the logical expression in the antecedent to confirm that it is still true. It then re-evaluates the expressions in each action. If it can evaluate all of them, then it executes the actions all at once and completes.
If the rule times out while it is waiting for a variable, it wakes up and tries one last time to evaluate the expressions in each action. If it can, it executes the actions all at once and completes. Otherwise, it completes without executing any of the actions, and the rule is rescheduled for the task queue.
Highlighting Rules for Tracing
You can highlight rules while they are being scanned, focused upon, or invoked to watch the patterns of data seeking (backward chaining) and event updating (forward chaining). To highlight rules, select Run Options from the Main Menu, then select highlight invoked rules from the Run Options menu.When G2 invokes a rule while highlighting is in effect, the rule is shown in reverse video until G2 completes evaluation of the rule. If G2 must backward chain to evaluate the antecedent, it keeps the first rule highlighted until it either finds the necessary values for the rule or a timeout occurs. Next, G2 highlights the rule to which it chained, and so on, until the values sought are found. After the values are found, G2 stops highlighting each rule in reverse order.
During forward chaining, G2 highlights a rule until it is finished evaluating the rule, then G2 goes on to highlight each rule to which it forward chains. This pattern is the same one used by G2 for focus and invoke actions.
Every rule that G2 scans blinks once per scan interval. Note that any of these patterns may be difficult to detect if several occur with the same rules during the same time period.
When G2 is highlighting rules, it runs at a lightly slower speed, pausing for three tenths of a second after highlighting each rule. The pauses make it possible for you to see more readily which rules are being invoked, and the order in which they are invoked by G2. To stop highlighting rules as they are invoked, and to return Q to its regular speed, select Do not highlight invoked rules from the Run Options menu.
6. Exemple de supervisió amb SE
This section shows the described procedure used for developing a KB for fault diagnostics in a laboratory plant by means of the framework. The organisation of the KB is shown after the laboratory plant description. And, finally, some relevant aspects observed in the validation over the real process are explained.
The Laboratory Plant
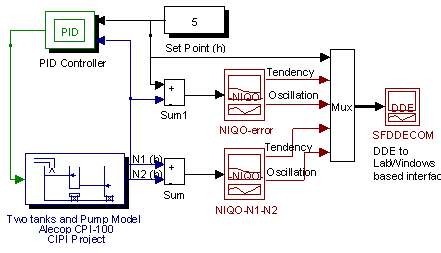
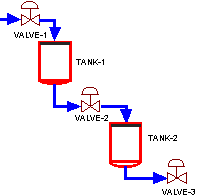
The plant to which fault situations are created is composed of two coupled tanks with two pipes connecting them as depicted in the following picture :
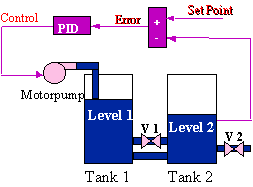
The Plant
The control goal is to control the level in the second tank by pumping fluid to the first tank while liquid flows out through valve 2 (V2). The control signal is the pump voltage. Measures of the tank levels are available too. Correct operation are defined as follows: valves (V1 and V2) are open and the process is correctly controlled (good PID tuning and pump working). When failures are introduced then the expert diagnostic system has to be able to detect and identify them. Therefore, the goal of the supervisory system is to track the process and detect situations that incite failures or process malfunctions, as well as to know when the process works in the normal operating conditions.The system will correctly work when the level of tank 2 tracks the setpoint through good regulation by action on the pump whilst valves 1 and 2 are open. In hypothetical case that the pump did not work, or any valve was closed, or the ambiguous "no good regulation" occurs then this would be considered as a system fail. So, possible malfunction causes will be:
Situations with multiple malfunctions that could simultaneously happen are not, in this example, expected. Use of an ES dealing with fault detection makes possible a study of the process evolution for each malfunction in order to obtain expert knowledge that allows rule conception and construction.Valve 1 is closed Valve 2 is closed The electrical pump does not work Bad regulation
Developing the Expert System Using a MATLAB Based Model
Several process simulations were executed during the KB development. They gave necessary knowledge for choosing significant variables to design this KB. Finally, selected signals were: tank levels difference level1-level2 and Error signal. Evolution of these signals, obtained from different simulated situations, gave us the experience to build up a complete KB based on qualitative and quantitative information. The knowledge extracted from simulations is written as rules. For example:
[W] When regime is transient and set point has not changed: And these rules are directly coded into G2 workspaces (and subworkspaces). They will be activated when the [W] condition stands. The activation of a workspace means that the rules [R] it contains are able to be fired.[R] If tendency of (level1-level2) is descending or greatly descending then conclude that valve1 is opened.
[R] If (level1-level2) >=9 and tendency of (level1-level2) is rising or greatly rising then conclude that valve1 is closed.
If (.../...) then conclude (.../...)
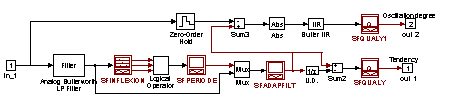
The KB obtained by following this procedure uses qualitative and quantitative information in its antecedents to deduce qualitative intermediate facts and final conclusions. Thus, abstractive procedures are needed to provide with this kind of information to the ES from the process signals. These procedures will be different for each process and each process signal. Moreover, the type of wished information will be also determinant to design an abstractive tool. In each situation a previous analysis of signal must be done and several techniques can be used (filtering, histograms, events generation, statistics, qualification, ...). In this example a set of operators has been developed (they involve filtering, zones qualification, singular points detection, and combination of them) under Simulink environment. For signals in this example chosen (level1-level2 and Error) the qualified tendency and oscillation degree were needed to provide with necessary antecedents to KB rules. They are depicted in the following schemes
Noise filtering.
Detection of maxima, minima and inflexion points.
Signal period estimation.
Low-pass filtering using a
cut-off frequency proportional to inverse of estimate period.Differentiate. Subtraction from original signal.
Qualification in Zones. Absolute Value.Filtering.
Qualification in Zones.
Tendency Oscillation Degree
According to this procedure, a numeric to qualitative abstractive process is performed by the Matlab/Simulink CACSD environment. In this example, the user can take advantage of ToolBoxes provided by Matlab for filtering and similar signal processing tasks.
The following picture shows how in the Simulink environment the signal abstraction and model representation for this example is organised. The block on the right hand-side is designed to perform DDE from Simulink to LabWindows based interface.
In the following sections, original names for signals are preserved ( Level1-level2 ® n1-n2 ) to maintain the original syntax of KB rules.
The G2 Knowledge Base
Several workspaces must be built by using G2 for developing ESs. They contain object definitions and expert rules. Some of the workspaces contain subworkspaces as a way to organise the knowledge complexity (knowledge itself and focusing capabilities) by means of activating and deactivating these subworkspaces depending upon rules from main workspaces.
Here follows the set of examples, classes, and rule definitions for each workspace:
RESERVOIRS - DONNEES workspace.
from class GSI-FLOAT-CLASS from class GSI-SYMBOL-CLASS
error sten_n1_n2 (level1-level2 tendency)
n1_n2 (level difference) sten_ error (error tendency)
consigne (set point) sosc_ n1_n2 (level1-level2 oscillation)
commande (control) sosc_ error (error oscillation)
stime (current time)
|
|
|
| [0 , 150) | Récent (recent) |
| [150 , 500) | Proche (near) |
| [500 , ¥ ] | Éloigné (remote) |
Symbolic variables tendencies
and oscillations of n1_n2 and error variables will
be used to obtain the process regime:
and conclude that comande is -- and conclude that Pompe is --
if not (cc is recent) and n1-n2 > 10 then conclude that V1 is fermee
if not (cc is recent)
and n1-n2>0.5 and n1-n2<4 and error>0.5 then conclude that V2 is ouverte
and conclude that pompe is cassee
if not (cc is recent) and n1-n2>3 and n1-n2<7 and error>0.5 then
conclude that V2=the value of V2 as of 0 datapoint ago and conclude
that pompe=the value of
pompe as of 0 datapoint ago
if not (cc is recent) and n1-n2>=9 and ( sten_n1-n2 is augmenter or sten_n1- n2 is augmenter_beaucoup) then conclude that V1 is fermee
if cc is loigne and v1
is ouverte and v2 is ouverte and pompe is bonne then conclude that com
is pas_bonne
régime (regime)
pompe
(Pump status)
cc (setpoint changing)
com (Control status)
V1 (V1 status)
fonctionnement (General status)
V2 (V2 status)
Values of these variables are deduced from rules of other workspaces (RULES-2 and RULES-3), except fonctionnement, which is deduced by rules of its own workspace. Claim fonctionnement is normal if V1 is ouverte (open) or inconnue (unknown), V2 is ouverte or inconnue, pompe is bonne (good state) or inconnue and com is bonne or inconnue, if one of these variables has a different value then claim fonctionnement is anormal.
These variables are not GSI
variables because they are easier to be manipulated by rules (by the easy
command set for changing the value of GSI variables). To define
GSI variables for sending conclusions to LabWindows is necessary. That
is why the workspace GSI-PC is created.
G2 supports three types of inference engine (forward chaining, backward chaining and combined forward/backward chaining) so that rules are fired (activated) in different ways. Moreover, the focus mechanism uses of the meta-knowledge to invoke specific groups of rules when is needed for dealing concurrently with multiple problem areas.This KB is only dealt by the forward chaining inference engine and rules are not periodically scanned. They are fired when any variable changes of value. This is because all variables have the capability do forward chaining, and every time any change occurs then all rules that use this variable could be fired. This reasoning is represented in last figure.
Resultats
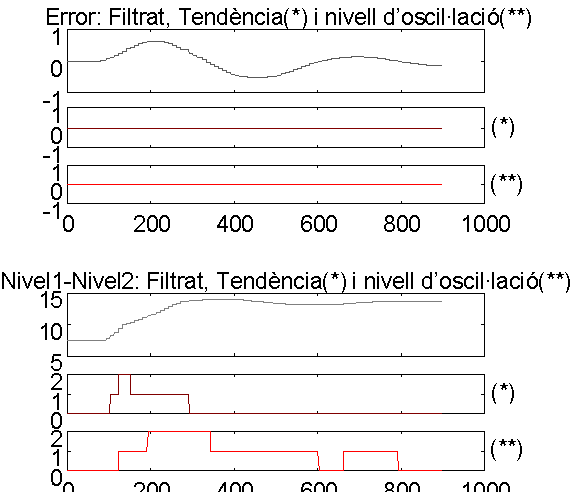
In the following plots temporal evolution of variables can be observed. Tendencies and oscillation degree are represented as well, as the filtered signal of n1-n2 and error signals. A table is added below each figure. This table shows the conclusion obtained for the ES regarding introduced failures.
About the Significant Information
The n1-n2 gives significant information by means of the qualified signal processing qualified tendencies and qualified oscillations, that are called abstractors. These abstractors are both implemented in Matlab/Simulink and LabWindows. For example, at t = 50 seconds a fault is introduced by closing V1. 50 seconds later the abstractor of n1-n2 tendency turns into monter what implies the effect of the failure is then detected. At that moment the ES could use this detection to infer the possible cause: the regime is transient but there is so far no abnormal situation. The abnormal situation is detected at t = 125 seconds when the qualified tendency is monter beaucoup (a lot) and qualified oscillation is detected as faible (slight). Thus, the ES has the sufficient significant information to detect the abnormal situation and, moreover, to diagnose the failure "V1 is close".
About the Diagnostic Results
Time to detect and diagnose was about 50 seconds, one third of the response time constant, after introduced failures into the system. At every case, conclusions obtained from temporal evolution are satisfactory and causes of failures are fairly well diagnosed without uncertainty. This last is very useful since G2 is not good enough in dealing uncertainty. Note, anyway, these KB is developed under the assumption that only failure is introduced at a time.
RESULTATS
|
|
|
|
|
|
|
|
|
|
|
|
|
nent |
sitori |
sitori |
sitori |
permanent |
nent |
permanent |
nent |
|
|
V1 |
|
|
|
|
|
|
|
|
|
|
V2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7. Conclusions
Hem presentat aquí una possible visió del que vol dir aplicar SE per a supervisió de processos amb ordinador. Hem mostrat el que vol dir IA, SE i perquè es necessiten en supervisió així com les característiques més importants de G2, especialment el motor dInferència a temps real. Al final hem mostrat el desenvolupament duna base de coneixement (KB). Aquest exemple sha fet sobre un procés real aplicant-hi monitoritzadors comercials (LabWindows), plataformes PC i SUN, i un sistema expert comercial com és el G2. Desenvolupar KB és més fàcil per lenginyer de control i de procés si disposa deines CACSD (com Matlab/Simulink).En lexemple sempra el SE G2 per fer diagnòstics. És de ressaltar que :
Al mateix temps, qualcuns problemes shan presentat :El processat de senyal sha resolt amb Matlab/Simulink com a primer pas per a labstracció dinformació que sigui útil pel SE. També sempra com a simulador que és utilitzat pel SE per validar accions de forma predictiva. LabWindows és el cor funcional del sistema de supervisió doncs com a sistema SCADA captura amb targes dadquisició de senyals tota la informació que requereix el sistema supervisor i loperari humà amb una bona interfase gràfica. Serveix de pont de comunicacions entre G2, Matlab/Simulink, el procés i loperari humà mateix. Varis motors dinferència són utilitzables en G2 (forward/backward chaining), encara que a lexemple només sha emprat el forward chaining. De fet, laplicació de forward chaining amb només tres nivells de profunditat (dencadenament premissa-conclusions de les regles) és laplicació més extesa de les aplicacions industrials de SE supervisors. Les capacitats de Temps Real en el motor dinferència de G2 han pogut ser testades en simulació durant la fase de desenvolupament de la Base de Regles (de la Base de coneixement), i finalment validades en el procés real. En definitiva, els SE són laplicació natural de la IA a nivell supervisor, i presenten dificultats en la seva aplicació doncs solen tenir temps de resposta alts que no els fan aplicables a un cert nombre de processos industrials ràpids. Altres problemes que presenten és la necessitat demprar informació imprecisa però significativa tal com fan els experts humans, el que podríem anomenar percepció no visual, per tal de poder aplicar els SE a processos industrial molt complexes amb un cost de desenvolupament acceptable de les Bases de Coneixement.El motor dinferència de G2 no suporta adientment el manejament de certesa (raonament aproximat) en lactivació de les regles. Aleshores, si es necessita es recomana dutilitzar altres SE. De totes maneres, aquest problema es resol parcialment proveint a G2 de bona informació qualitativa mitjançant eines dabstracció. Matlab/Simulink no és un simulador perfecte: quan més complicat sigui el procés tant més temps pren de simulació. Això no el fa indicat per ser utilitzat en la supervisió de processos industrials complexes (molts subprocessos i/o processos multivariables que implica múltiples llaços de control). Encara així i tot, MATLAB és una bona plataforma per desenvolupar eines dabstracció. Parlant de temps real, el màxim període de mostreig que permetia G2 era dun segon. Per sota daqueixa barrera els mecanismes de manejament de TR de G2 no funcionen de forma garantida. El fet de tenir un temps de resposta tan lent només el fa aplicable a processos industrials lents, que en són una majoria.
Per saber-ne més :
Download this document